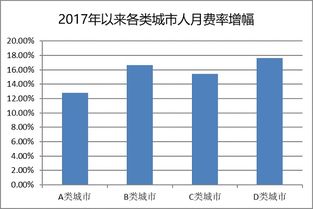
在信息技術應用創新產業加速發展的背景下,硬件設備與國產操作系統的深度適配成為關鍵一環。東芝復合機在國產化適配進程中取得顯著進展,成功實現了與統信UOS操作系統的無縫對接,為北京及全國的用戶提供了更安全、高效、便捷的文檔處理解決方案。
這一適配成果意味著,搭載UOS系統的計算機能夠直接、順暢地調用東芝復合機的打印、掃描、復印等各項功能,無需復雜的中間轉換或兼容層。對于北京地區眾多推進信息化建設的政府機構、企事業單位及教育科研用戶而言,此舉有效解決了在國產軟硬件環境中高效處理紙質與電子文檔的實際痛點,保障了辦公流程的連續性與數據的安全性。
東芝與統信軟件的技術服務團隊緊密合作,針對UOS系統的底層架構與安全機制進行了深度優化。適配工作不僅確保了基本功能的穩定運行,還充分考慮了國內用戶的使用習慣,在驅動安裝、網絡配置、權限管理及高級功能調用等方面提供了簡潔明了的操作指引。北京作為技術服務與支持的中心,能夠為用戶提供快速響應的本地化服務,確保從部署到運維的全周期體驗。
此次無縫對接,是東芝積極響應中國市場國產化需求、深化本土合作的重要體現。它標志著外資辦公設備品牌在信創生態建設中邁出了堅實一步,也為整個行業提供了硬件與國產操作系統協同創新的成功范例。隨著適配的深入與推廣,預計將進一步提升UOS生態的完善度與用戶滿意度,助力我國自主信息產業生態的蓬勃發展。